Earlier this year, I was talking to Kurt Mammen, who’s teaching 357, and he mentioned that he’d surveyed his students to see how much time they were putting into the course. I think that’s an excellent idea, so I did it too.
Specifically, I conducted a quick end-of-course survey in CPE 430, asking students to estimate the number of weekly hours they spent on the class, outside of lab and lecture.
Here are some pictures of the results. For students that specified a range, I simply took the mean of the endpoints of the range as their response.
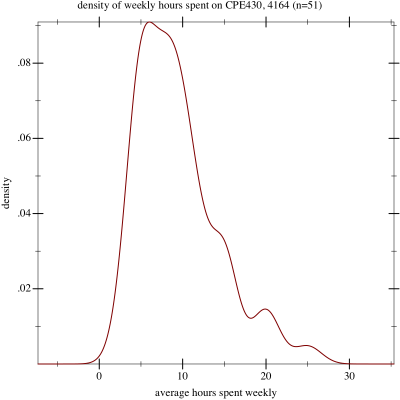
Density of responses
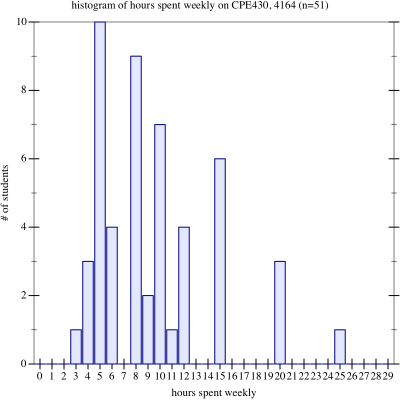
Then, for those who will complain that a simple histogram is easier to read, a simple histogram of rounded-to-the-nearest-hour responses:
Histogram of responses
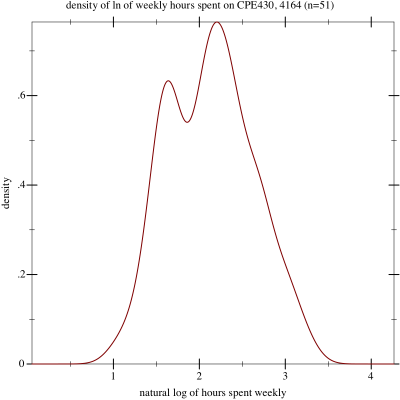
Finally, in an attempt to squish the results into something more accurately describable as a parameterizable normal curve, I plotted the density of the natural log of the responses. Here it is:
Density of logs of responses
Sure enough, it looks much more normal, with no fat tail to the right. This may just be data hacking, of course. For what it’s worth, the mean of this curve is 2.13, with a standard deviation of 0.49.
Oh mainstream programmers, how I hate thee. Let me count the ways.
The following is a question taken from the “AP Computer Science Principles Course and Exam Description,” from the College Board:
A programmer completes the user manual for a video game she has developed and realizes she has reversed the roles of goats and sheep throughout the text. Consider the programmer’s goal of changing all occurences of “goats” to “sheep” and all occurrences of “sheep” to “goats.” The programmer will use the fact that the word “foxes” does not appear anywhere in the original text.
Which of the following algorithms can be used to accomplish the programmer’s goal?
a)
First, change all occurrences of “goats” to “sheep.”
Then, charge all occurrences of “sheep” to “goats.”
b)
First, change all occurrences of “goats” to “sheep.”
Then, charge all occurrences of “sheep” to “goats.”
Last, charge all occurrences of “foxes” to “sheep.”
c)
First, change all occurrences of “goats” to “foxes.”
Then, charge all occurrences of “sheep” to “goats.”
Last, charge all occurrences of “foxes” to “sheep.”
d)
First, change all occurrences of “goats” to “foxes.”
Then, charge all occurrences of “foxes” to “sheep.”
Last, charge all occurrences of “sheep” to “goats.”
This question makes me angry. Why? Because the obvious lesson from this example is that YOU SHOULD NOT BE MODELING COMPUTATION AS A SEQUENCE OF MUTATIONS.
In other words, the correct answer is this:
e) For each word in the document, replace it using this function: * if the word is “goats”, return “sheep” * if the word is “sheep”, return “goats” * otherwise, return the word unchanged.
Voila. Problem solved. No resorting to nasty swap ideas.
At a lower level, I think the core problem may be the inability of the English language to handle this kind of abstraction. Notice that in my proposed solution (e), I tread dangerously close to mathematical notation; it’s not really purely English any more.
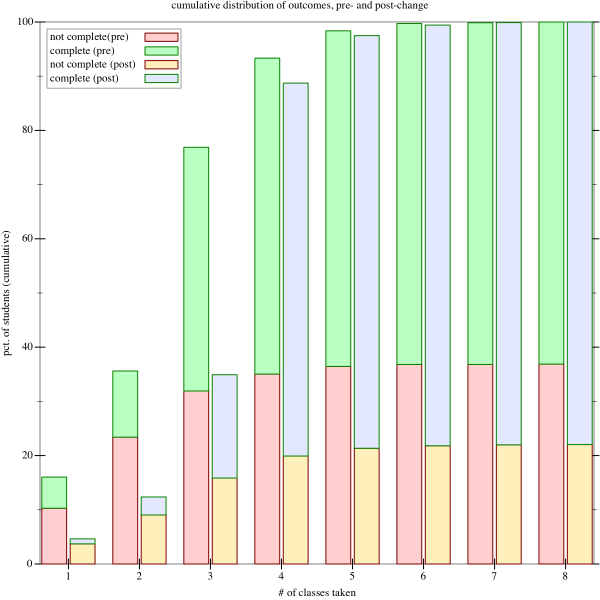
This compares the outcomes in the years 2005 through 2009, before we instituted 123, with the outcomes in the years since. This is a cumulative graph, showing for a number of classes how many students finished by taking that many classes or fewer, and whether they succeeded or failed. Success is defined as having gotten a grade of C- or better in 103 (that is, the condition that allows them to continue with higher-level classes in the major).
So, for instance, we see that in the years before 123 was added, more than 90% of students took four classes or fewer, and that about 38% of those students did not successfully finish. In the years after 123 was added, slightly less than 90% of students took four classes or fewer, and of those, only about 23% left without finishing.
The big picture here is the post-change years have a much lower dropout rate; our first-year retention has improved from 63% to 77%, a dramatic increase.
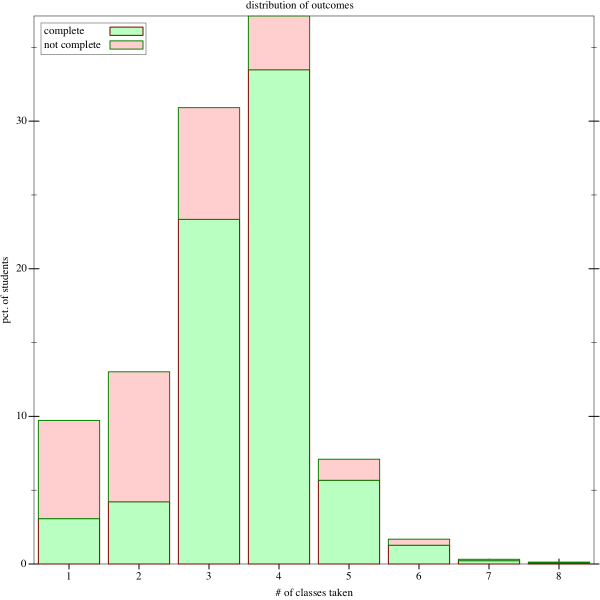
Here’s a pair of pictures showing the distribution of # of classes taken in the first-year curriculum. There are only four classes, so this is really a picture of students repeating classes, and how many times they repeat them. So, for instance, we see that about 8% of students take exactly five courses (most likely repeating one), and that in this group, approximately 85% are then finished successfully.
first-year student outcomes
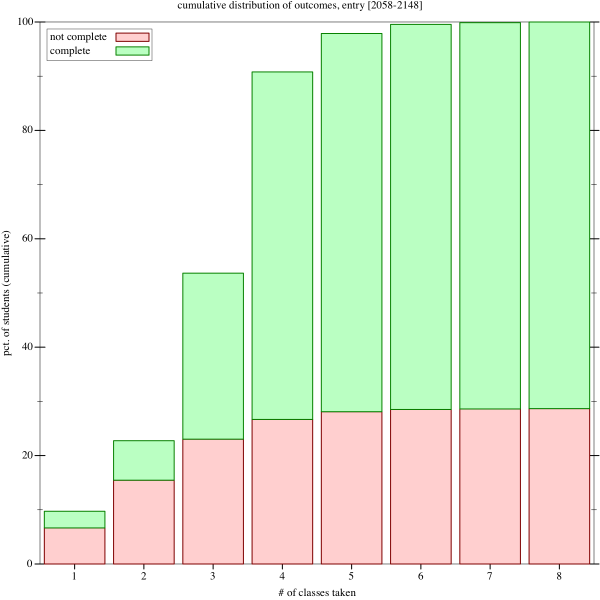
This graph shows the cumulative distribution; it’s just the discrete integral of the prior picture.
cumulative first-year student outcomes
Note that a lot of people come in with AP credit, and skip one or more classes, which is why we see a lot of people finished after one or two classes.
It’s also interesting how many people stop after one or two classes. You can look at that either as bad news or good, depending on whether you see these students as promising ones that we squandered, or students that quickly discovered that computer science was not for them.
Also note that since these pictures span 2005 to 2015, they cover the period from 2005–2010 when the course sequence was only three courses long. The obvious next step is to split these graphs into two graphs, to see whether the addition of 123 to the curriculum had a major effect.
First, a disclaimer: I can’t imagine this will be interesting to anyone not at Cal Poly. I’m using these blog posts as a way of dumping a bunch of interesting-to-me graphs and visualizations of the behavior of students in our first-year sequence here at Cal Poly.
Using racket and OpenGL, I generated movies showing individual students (each one represented as a blue square) moving through our first-year sequence. This data is based on information about grades earned by students in our courses from Winter 2005 through Winter 2016.
The four columns represent the courses in our first-year sequence: CPE 123, CPE 101, CPE 102, and CPE 103. Note that CPE 123 was not offered before Fall 2010.
Time is represented as time in the animation. That is, the first thing you’ll see is a bunch of students entering the program in 2005. The vertical placement of the dot represents the grade they got in the course (with some noise added to prevent all students from landing on top of each other).
Notice that the reduced size (480p) makes the animation run smoother. You can full-screen it to see it better. There’s also a higher-resolution version that I made, but it looks to me like it doesn’t actually convey any more information.
Finally, I really should figure out how to slap text on the screen as part of an OpenGL animation, so that I can label the thing.
I’ve done a lot of programming in Racket. A lot. And people often ask me: “What do you think of Racket? Should I try it?”
The answer is simple: No. No, you should not.
You’re the kind of person who would do very badly with Racket. Here’s why:
All those parentheses! Good Lord, the language is swimming in parentheses. It’s not uncommon for a line to end with ten or twelve parentheses.
Almost no mutation! Idiomatic Racket code doesn’t set the values of variables in loops, and it doesn’t set the values of result variables in if branches, and you can’t declare variables without giving them values, and Racket programmers hardly ever use classes with mutable fields. There’s no return at all. It’s totally not like Java or C. It’s very strange and unsettling.
Library support. Yes, there are lots of libraries available for Racket, but there are many more in, say, Python. I think there are currently fifty-five thousand packages available for Python.
Racket is an experimental language: when the Racket team decides that the language should change, it does. Typed Racket is evolving rapidly, and even core Racket is getting fixes and new functionality every day.
Racket is not a popular language. You’re not going to be able to search for code snippets on line with anything like the success rate that you’d have for JavaScript or Python or Java.
Racket will ruin you for life as a Java developer. You will be agonizingly aware of how much boilerplate you’re cranking out, and after every hour of shoveling Java, you will sneak off to the bathroom and write a tiny beautiful macro that no one will ever be allowed to see or use.
If none of these succeed in scaring you off, well, then, go ahead and give it a try. Just remember: I warned you.
I love knowing that I have powers and knowledge that other people don’t.
I want to talk about that last one. It’s the one I’m least comfortable talking about, and I think it’s somewhere near the center of a number of discussions I’ve had with others and with myself about motivation, teaching, and the future of Computer Science.
A few days ago, I picked up G.H. Hardy’s A Mathematician’s Apology again. He is, to be blunt, an unreconstructed bigot in the area of Native Mathematical Ability. He believes that either you got it or you ain’t, and if you do, it is a thing that sets you apart from other men. (Not from other women, because in the 1920s, everyone was a man. Look it up.)
On the one hand, I can see the appalling lack of mental rigor in some of his arguments. I won’t go point by point, but it appears to me that the nailed-down-mathematical-argument part of his brain simply wasn’t engaged when he made arguments like the assertion that in general those with mathematical talent aren’t likely to have any other useful one.
Nevertheless, much of his thinking pervades mine. I think that thinking such as his fuels much of my own drive (such as it is), and indeed is relatively close to my central joy in life.
Let me put it differently, and more positively: Richard Feynman writes about the simple joy of discovering things for oneself. I completely subscribe to this. Yesterday, of my own accord, I examined the notion of continuity on functions from the reals to the reals and the more general one of continuity on topological spaces, and convinced myself that they’re perfectly aligned (on the functions from reals to reals). That’s a really beautiful thing, and I wanted to run around and tell everyone about it (and here I am doing that). I got to figure that out for myself, and that was a beautiful thing.
Let’s dig a little deeper, though, and try to understand why that should be a beautiful thing. Why is it thrilling to know things, or even better to discover them for ourselves?
Ultimately, I think that it comes down to this: it gives us power, and fuels our egos.
That doesn’t sound very nice, does it?
Well, in many ways it’s the same thing that drives us to work hard at anything. Why do we run races? Why do we compete at Golf? Why do we work hard for promotions, or try to explore new lands? Why do we … do anything?
Well, on a basic level, we’re trying to survive as a species. In order to do this, every individual is programmed to pull hard, to do her very best work, to train harder than the other guy.
When we put it that way, it doesn’t sound so bad. Survival of the species, and more locally, survival of our own DNA. I want to be the best at something, in order to give my DNA a competitive advantage. This is locally visible as an advantage over other people, but manifests itself globally as a path toward improving the survival of the species.
Looking at it in the global context, though, tempers the drive for individual success; my success benefits the species only when it doesn’t come at the expense of the species as a whole. If I try to ensure the success of my genes by eliminating those around me, I’m not benefitting the species, I’m hurting it, and I won’t be around very long.
So, what do we have? We’ve developed a system where we compete—to a point. We compete in venues where our individual success leads to improvement for our families, our communities, and our species.
But enough about you.
What does this mean for me?
When I was a child, I did well at math. I understood things easily, and none of the concepts gave me trouble. When there was an interesting new concept, I spent a bit of time thinking about it, and then I understood it. I got the same kind of satisfaction from math that you might from a video game: a bit of work, and lots of instant gratification. To be sure: I had a privileged upbringing, and lots of attention from teachers to help me succeed. I have relatively few illusions about the part that my background made in my success.
It’s no surprise, then, that I chose to focus on math; Math class was my favorite, and until college, I could convince myself that I was the best in every class (following Hardy here, I’ll suggest that some mild egotism is not out of place here—it’s helpful to believe that you’re the best, even when the evidence is weak).
In college, I discovered lots of folks that were better mathematicians than I was.
Hmm… I can see that I’m going astray here; from a discussion intended to be about the motivations of programmers and programming students, I’m drifting over into nature-vs-nurture.