Yeast feeding notes
Back in San Luis Obispo, now, and once again yeast is extremely happy. But wait… rewind!
Back in San Luis Obispo, now, and once again yeast is extremely happy. But wait… rewind!
Today was a spectacular beautiful Maine morning on Blue Hill bay. Especially at 7:00 AM. How do I know this? Today was the 21st running of the long island swim. Or the Granite (Wo)Mon. Or whatever you want to call it. This means that it was also the TWENTIETH ANNIVERSARY of the silly idea. Only five more years until the quarter-century….
This year’s edition was organized by organizer extraordinaire Mary Clews, and it went off without a hitch. The water was extremely warm (and yes, this is not good for the fauna), and the water was pretty much glassy smooth. There were enough chase boats, and everyone finished in a reasonable time. Yay!
Special mention this year is made of Amanda Herman, who is a first time swimmer and I have no idea how fast she was because she was way way ahead of me the whole time. Great Job!
Swimmers:
Crew:
End-of-swim Hosts (tea and towels, many thanks!):
Traveling across the country with yeast. Hard. On the way out here I slopped a bit in a ziploc bag, and though I’d been planning to give the TSA guys some lame story when they pointed out that the bag was way bigger than 3.5 ounces, in the event I actually forgot about it completely, and they missed it on the scan or decided to give me a pass.
I got to Connecticut, and it was still pretty healthy. I feel self-righteous about only feeding my yeast unbleached flour, but basically, it was bubbling along just fine.
Then I brought it to Maine.
So here I am grading another exam. This exam question asks students to imagine what would happen to an interpreter if environments were treated like stores. Then, it asks them to construct a program that would illustrate the difference.
They fail, completely.
(Okay, not completely.)
By and large, it’s pretty easy to characterize the basic failing: these students are unwilling to break the rules.
Ron Yorita wrote a great thesis. I need to make it easier to find the various parts of his great work.
So, I just bought a copy of Screenflow, an apparently reputable piece of screencasting software for the mac. They sent me a license code. Now it’s time to enter it. Here’s the window:
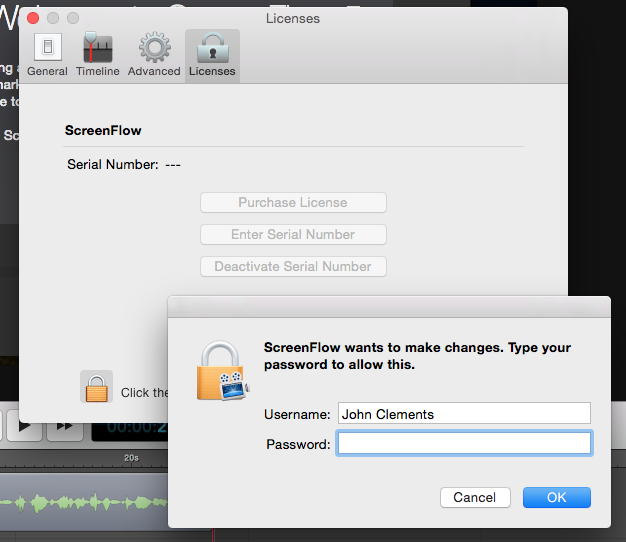
Hmm… says here all I need to do is… enter my admin password, and then the license code.
Wait… what?
Why in heaven’s name would Screenflow need to know my admin password here?
My guess is that it’s because it wants to put something in the keychain for me. That’s not a very comforting thought; it also means that it could delete things from my keychain, copy the whole thing, etc. etc.
This is a totally unacceptable piece of UI. I think it’s probably both Apple’s and Telestream’s fault. Really, though, I just paid $100 and now I have to decide whether to try to get my money back, or just take the chance that Telestream isn’t evil.
Good news, students. I can’t accurately predict your final grades based solely on your first two assignments, quizzes, and labs.
I tried, though…
First, I took the data from Winter 2015. I separated the students into a training set (70%) and a validation set (30%). I used ordinary least-squares approximation to learn a linear weighting of the scores on the first two labs, the first two assignments, and the first two quizzes. I then applied this weighting to the validation set, to see how accurate it was.
Short story: not accurate enough.
On the training set, the RMS error is 7.9% of the final grade, which is not great but might at least tell you whether you’re going to get an A or a C. Here’s a picture of the distribution of the errors on the training set:
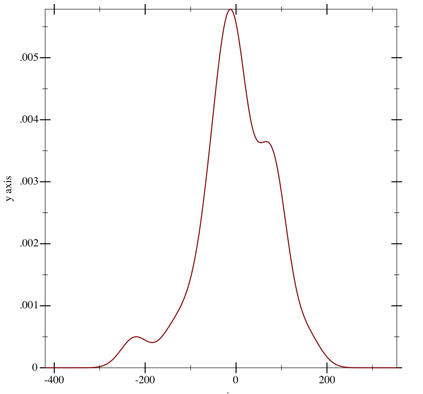
distribution of errors on training set
The x axis is labeled in tenths of a percentage point. This is the density of the errors, so the y axis is somewhat unimportant.
Unfortunately, on the validation set, things fell apart. Specifically, the RMS error was 19.1%, which is pretty terrible. Here’s the picture of the distribution of the errors:
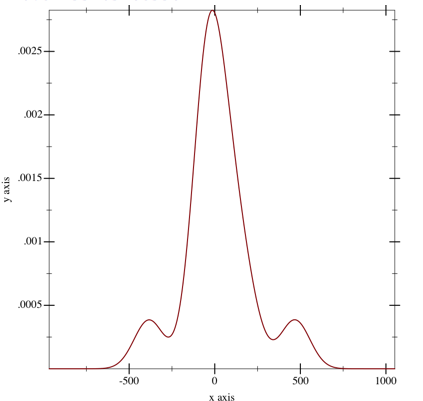
distribution of errors on validation set
Ah well… I guess I’m going to have to grade the midterm.
TL;DR: Molis Hai
Randomly generated passwords:
More randomly generated passwords:
Yet More randomly generated passwords
Which of these look easiest to remember?
All three of these sets of passwords are randomly generated from a set of 2^56; they’re all equivalently secure. The second ones and the third ones are generated using markov models built from the text of Charles Dickens’ A Tale Of Two Cities, where transitions are made using Huffman Trees.
The secret sauce here is that since traversing a Huffman tree to a common leaf requires fewer bits than traversing that same tree to reach a deep leaf, we can drive the generating model using a pool of bits, and use varying numbers of bits depending on the likelihood of the taken transition.
This means that there’s a 1-to–1 mapping between the sequences of bits and the corresponding English-like textual fragments, thus guaranteeing the security of the passwords (or, more precisely, reducing it to the problem of generating a cryptographically secure sequence of bits, which many smart people have thought hard about already).
Another reasonable way to describe this process is that we’re just “decompressing” randomly generated crypto bits using a model trained on Dickens.
The only difference between the second and third pools is that the second one uses a 2nd-order markov model—meaning that the choice of a letter is driven by the prior 2—and that the third one uses a 3rd-order model, resulting in more Dickensian text—but also in longer text.
Naturally, you can push this further. When you get to a 5th order model, you get passwords like this:
Much more Dickensian, much longer. Same security.
You can try it out yourself; Molis Hai contains a small JS implementation of this, and a canned set of 2nd-order trees.
Please note that there’s nothing secret about the model; we’re assuming that an attacker already knows exactly how you’re generating your passwords. The only thing he or she is missing is the 56 bits you used to generate your password.
For a more carefully written paper that explains this a bit more slowly, see the preprint at ArXiv.
Naturally, you can use any corpus you like. I tried generating text using a big slab of my own e-mails, and aside from a serious tendency to follow the letter “J” with the letters “o”, “h”, and “n”, I didn’t notice a huge difference, at least not in the 2nd-order models. Well, actually, here’s an example:
It’s probably true that Charles Dickens wasn’t quite so likely to type “avascript” as I am. Or “html”.
To read the Racket code I used to generate the models, see github.
And for Heaven’s sake, let me know about related work that I missed!
Why are these things stuck in my head? They pop out all the time, and I can’t for the life of me figure out why.
One of my children is in third grade. As part of a “back-to-school” night this year, I sat in a very small chair while a teacher explained to me the “Math Practices” identified as part of the new Common Core standards for math teaching.
Perhaps the small chair simply made me more receptive, taking me back to third grade myself, but as she ran down the list, I found myself thinking: “gosh, these are exactly the same skills that I want to impart to beginning programmers!”
Here’s the list of Math Practices, a.k.a. “Standards for Mathematical Practice”:
Holy Moley! Those are incredibly relevant in teaching programming. Furthermore, they sound like they were written by someone intimately familiar with the How To Design Programs or Bootstrap curricula. Indeed, in the remainder of my analysis, I’ll be referring specifically to the steps 1–4 of the design recipe proposed by HtDP (as, e.g., “step 2 of DR”).
Let’s take those apart, one by one:

