Posts tagged Programming Languages
Reading Daniel Dennett’s “From Bacteria to Bach and Back” this morning, I came across an interesting section where he extends the notion of ontology—a “system of things that can be known”—to programs. Specifically, he writes about what kinds of things a GPS program might know about: latitudes, longitudes, etc.
I was struck by the connection to the “data definition” part of the design recipe. Specifically, would it help beginning programmers to think about “the kinds of data that their program ‘knows about’”? This personification of programs can be seen as anti-analytical, but it might help students a lot.
Perhaps I’ll try it out this fall and see how it goes.
Okay, that’s all.
Why, professor Clements, why? Why are you taking all of our loops away?
I feel like the Grinch, sometimes, taking all of the pretty little candy loops away from the wide-eyed first-year students.
But the fact is… that I really don’t like loops.
-
Loops in every popular language simply execute a block of code repeatedly. This means that your code has to perform mutation in order to allow a value to escape from the code. This requires before-and-after reasoning, and introduces a huge new source of bugs into your program. By contrast, there’s almost no chance to tangle the action of the caller and the callee in a recursive call.
-
Corollary of this: you can easily update loop variables in the wrong order: e.g.: i += 1, sum += arr[i]. Oops, bug.
-
Loops can’t easily be debugged; in a functional style, each loop iteration is a recursive call for which the student can write an explicit test. Not possible using loops.
-
In functional style, you can’t forget to update a variable; each recursive call must contain values for all loop variables, or you get a sensible (and generally statically detectable) error.
-
You can’t write a loop in a non-tail-calling fashion. You have to do all of the work on the way down. Traversing a tree is basically impossible (to do it, you’re going to wind up building a model of the stack, turing tar pit etc.).
-
Finally, writing in a functional style is about 80% of the way to proving your code correct; you have to choose a name for the action of the recursive call, and you can usually state an invariant on the relation between the inputs and the outputs without difficulty.
Nothing here is new; it’s just a way of blowing off steam while grading my students’ terrible, terrible code. Sigh.
(EDIT: I should add… none of this applies to list comprehension forms such as for/list; those are dandy. Not sure? Run down the list of bullet points and check for yourself.)
Okay, it’s week four of data structures in Python. In the past few days, I’ve read a lot of terrible code. Here’s a beautiful, horrible, example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 |
# An IntList is one of
# - None, or
# - Pair(int, IntList)
class Pair:
def __init__(self, first, rest):
self.first = first
self.rest = rest
# standard definitions of __eq__ and __repr__ ...
# A Position is one of
# - an int, representing a list index, or
# - None
# IntList int -> Position
# find the position of the sought element in the list, return None if not found.
def search(l, sought):
if l == None:
return None
rest_result = search(l.rest, sought)
if (l.first == sought or rest_result) != None:
if l.first == sought:
return 0
else:
return 1 + rest_result
|
This code works correctly. It searches a list to find the position of a given element. Notice anything interesting about it?
Take a look at the parentheses in the if line. How do you feel about this code now?
(Spoilers after the jump. Figure out why it works before clicking, and how to avoid this problem.)
It’s much closer to ‘go’ time now with Python, and I must say, getting to know Python better is not making me like it better. I know it’s widely used, but it really has many nasty bits, especially when I look toward using it for teaching. Here’s my old list:
- Testing framework involves hideous boilerplate.
- Testing framework has standard problems with floating-point numbers.
- Scoping was clearly designed by someone who’d never taken (or failed to pay attention in) a programming languages course.
- The vile ‘return’ appears everywhere.
But wait, now I have many more, and I’m a bit more shouty:
- Oh dear lord, I’m going to have to force my students to implement their own equality method in order to get test-case-intensional checking. Awful. Discovering this was the moment when I switched from actually writing Python to writing Racket code that generates Python. Bleah.
- Python’s timing mechanism involves a hideously unhygienic “pass me a string representing a program” mechanism. Totally dreadful. Worse than C macros.
- Finally, I just finished reading Guido Van Rossum’s piece on tail-calling, and I find his arguments not just unconvincing, not just wrong, but sort of deliberately insulting. His best point is his first: TRE (or TCO or just proper tail-calling) can reduce the utility of stack traces. However, the solution of translating this code to loops destroys the stack traces too! You can argue that you lose stack frames in those instances in which you make tail calls that are not representable as loops, and in that case I guess I’d point you to our work with continuation marks. His next point can be paraphrased as “If we give them nice things, they might come to depend on them.” Well, yes. His third point suggests to me that he’s tired of losing arguments with Scheme programmers. Fourth, and maybe this is the most persuasive, he points out that Python is a poorly designed language and that it’s not easy for a compiler to reliably determine whether a call is in tail position. Actually, it looks like he’s wrong even here; I read it more carefully, and he’s getting hung up on some extremely simple scoping issues. I’m really not impressed by GvR as a language designer.
I’m just getting started, but already Python is looking like a terrible teaching language, relative to Racket.
- Testing framework involves hideous boilerplate.
- Testing framework has standard problems with floating-point numbers.
- Scoping was clearly designed by someone who’d never taken (or failed to pay attention in) a programming languages course.
- The vile ‘return’ appears everywhere.
Oh mainstream programmers, how I hate thee. Let me count the ways.
The following is a question taken from the “AP Computer Science Principles Course and Exam Description,” from the College Board:
- A programmer completes the user manual for a video game she has developed and realizes she has reversed the roles of goats and sheep throughout the text. Consider the programmer’s goal of changing all occurences of “goats” to “sheep” and all occurrences of “sheep” to “goats.” The programmer will use the fact that the word “foxes” does not appear anywhere in the original text.
Which of the following algorithms can be used to accomplish the programmer’s goal?
a)
- First, change all occurrences of “goats” to “sheep.”
- Then, charge all occurrences of “sheep” to “goats.”
b)
- First, change all occurrences of “goats” to “sheep.”
- Then, charge all occurrences of “sheep” to “goats.”
- Last, charge all occurrences of “foxes” to “sheep.”
c)
- First, change all occurrences of “goats” to “foxes.”
- Then, charge all occurrences of “sheep” to “goats.”
- Last, charge all occurrences of “foxes” to “sheep.”
d)
- First, change all occurrences of “goats” to “foxes.”
- Then, charge all occurrences of “foxes” to “sheep.”
- Last, charge all occurrences of “sheep” to “goats.”
This question makes me angry. Why? Because the obvious lesson from this example is that YOU SHOULD NOT BE MODELING COMPUTATION AS A SEQUENCE OF MUTATIONS.
In other words, the correct answer is this:
e) For each word in the document, replace it using this function: * if the word is “goats”, return “sheep” * if the word is “sheep”, return “goats” * otherwise, return the word unchanged.
Voila. Problem solved. No resorting to nasty swap ideas.
At a lower level, I think the core problem may be the inability of the English language to handle this kind of abstraction. Notice that in my proposed solution (e), I tread dangerously close to mathematical notation; it’s not really purely English any more.
I’ve done a lot of programming in Racket. A lot. And people often ask me: “What do you think of Racket? Should I try it?”
The answer is simple: No. No, you should not.
You’re the kind of person who would do very badly with Racket. Here’s why:
-
All those parentheses! Good Lord, the language is swimming in parentheses. It’s not uncommon for a line to end with ten or twelve parentheses.
-
Almost no mutation! Idiomatic Racket code doesn’t set the values of variables in loops, and it doesn’t set the values of result variables in if branches, and you can’t declare variables without giving them values, and Racket programmers hardly ever use classes with mutable fields. There’s no return at all. It’s totally not like Java or C. It’s very strange and unsettling.
-
Library support. Yes, there are lots of libraries available for Racket, but there are many more in, say, Python. I think there are currently fifty-five thousand packages available for Python.
-
Racket is an experimental language: when the Racket team decides that the language should change, it does. Typed Racket is evolving rapidly, and even core Racket is getting fixes and new functionality every day.
-
Racket is not a popular language. You’re not going to be able to search for code snippets on line with anything like the success rate that you’d have for JavaScript or Python or Java.
-
Racket will ruin you for life as a Java developer. You will be agonizingly aware of how much boilerplate you’re cranking out, and after every hour of shoveling Java, you will sneak off to the bathroom and write a tiny beautiful macro that no one will ever be allowed to see or use.
If none of these succeed in scaring you off, well, then, go ahead and give it a try. Just remember: I warned you.
So here I am grading another exam. This exam question asks students to imagine what would happen to an interpreter if environments were treated like stores. Then, it asks them to construct a program that would illustrate the difference.
They fail, completely.
(Okay, not completely.)
By and large, it’s pretty easy to characterize the basic failing: these students are unwilling to break the rules.
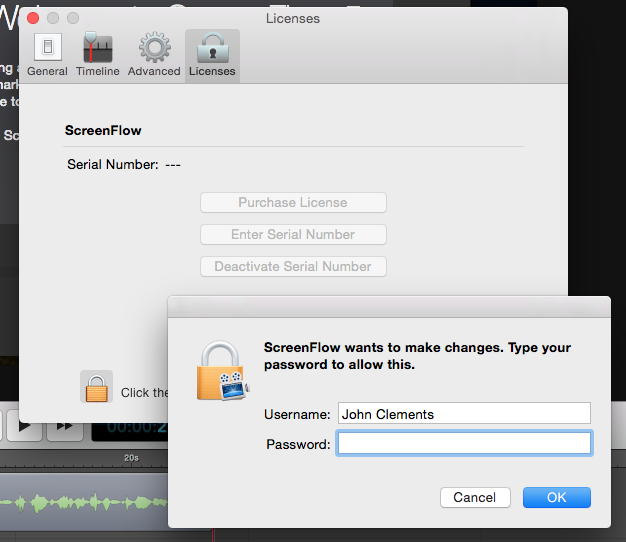
So, I just bought a copy of Screenflow, an apparently reputable piece of screencasting software for the mac. They sent me a license code. Now it’s time to enter it. Here’s the window:
Hmm… says here all I need to do is… enter my admin password, and then the license code.
Wait… what?
Why in heaven’s name would Screenflow need to know my admin password here?
My guess is that it’s because it wants to put something in the keychain for me. That’s not a very comforting thought; it also means that it could delete things from my keychain, copy the whole thing, etc. etc.
This is a totally unacceptable piece of UI. I think it’s probably both Apple’s and Telestream’s fault. Really, though, I just paid $100 and now I have to decide whether to try to get my money back, or just take the chance that Telestream isn’t evil.
One of my children is in third grade. As part of a “back-to-school” night this year, I sat in a very small chair while a teacher explained to me the “Math Practices” identified as part of the new Common Core standards for math teaching.
Perhaps the small chair simply made me more receptive, taking me back to third grade myself, but as she ran down the list, I found myself thinking: “gosh, these are exactly the same skills that I want to impart to beginning programmers!”
Here’s the list of Math Practices, a.k.a. “Standards for Mathematical Practice”:
- Make sense of problems and persevere in solving them.
- Reason abstractly and quantitatively.
- Construct viable arguments and critique the reasoning of others.
- Model with Mathematics.
- Use appropriate tools strategically.
- Attend to precision.
- Look for and make use of structure.
- Look for and express regularity in repeated reasoning.
Holy Moley! Those are incredibly relevant in teaching programming. Furthermore, they sound like they were written by someone intimately familiar with the How To Design Programs or Bootstrap curricula. Indeed, in the remainder of my analysis, I’ll be referring specifically to the steps 1–4 of the design recipe proposed by HtDP (as, e.g., “step 2 of DR”).
Let’s take those apart, one by one: