I think I’m not alone in suggesting that the tree, and perhaps the binary tree specifically, is the most foundational data structure in computer science.
This raises the question of how binary trees should be introduced, and I’d like to make the case that introducing binary trees as a special case of undirected graphs is not a good idea.
I can see reasons why you might think this is a good idea; they both involve connecting circles with straight lines on the board. If you take the general notion of a graph, and you happen to arrange the lines and circles in a particular way, it’s a tree. That kind of suggests that graphs are a generalization of trees, and that you might want to introduce trees as a special case of these graphs.
Please do not do this.
Specifically, my claim is that this produces a complex definition of trees with many global constraints, a definition which makes it very hard to prove some simple things.
Let’s see why.
Trees as Undirected Graphs
To begin with, consider the definition of a graph, a set of nodes along with a symmetric binary relation on nodes that we call “edges”.
In order to construct the set of trees, we can restrict this definition in the following ways.
A tree is a graph with the following properties:
We designate one node as the root node,
it is connected, and
it has no cycles.
The last two of these are global cqnstraints requiring complex checks, and verifying the third is genuinely quite complex, especially for a first-year student.
Suppose now that we want to identify the descendants of a node. This is where things start to get really unpleasant. The descendants of a node are the adjacent nodes that are not the parent node. But which is the parent node? The root node has no parent node. For other nodes, it is the adjacent node which is the first along the path to the root node. Again, this is not a simple process; if we provide a symmetric edge relation and a parent node, determining the path to the root node (and thus the parent node (and thus, by elimination, the descendants)) requires potentially a full search of the tree. Yes, this can be cached. Yes, it doesn’t matter whether you do a depth-first or breadth-first search. It’s still a lot of work.
But wait! Suppose we want a binary tree? Firstly, we must ensure that every node has at most two descendants, which is the same as ensuring that the root node has at most 2, and every other node has at most 3. That’s the easy part, though. In a binary tree we typically care whether a child is the left child or the right child; adding this to a graph representation requires labeling every node as either a left child or a right child, and then checking to make sure that no node has more than one left or right child.
Inductively Specified Trees
Okay, so what’s the alternative?
The alternative is the inductive specification of a binary tree: a binary tree is either an empty tree, or it is a node containing a left tree and a right tree.
This representation is essentially a tree by definition; no global checks are required. Asking whether a binary tree specified in this way is a binary tree is genuinely trivial: only binary trees can be specified using this schema.
You could argue that inductive specifications are hard for students, and I wouldn’t completely disagree, but I would also argue that the overwhelming simplicity of this definition of binary trees powerfully outweighs the challenge of becoming comfortable with inductive specifications.
Identifying the descendants of a node here is essentially trivial; an empty tree has no descendants, a non-empty tree lists its two descendants.
Freebie: this representation also sidesteps the irritating issues around identity which bedevil programmers everywhere.
What about directed graphs?
Trees as Directed Graphs
Directed graphs are considerably better than undirected graphs. But still way worse than the inductive specification. Specifically, you need an undirected graph that is connected and with no directed cycles, and you also need an additional constraint that at most one node points to another one (making the arbitrary choice that the edges point from parents to children). Checking these constraints still requires examining the whole graph. Identifying the child nodes is much nicer. Distinguishing the left and right children is still a serious problem.
Done
To summarize; it’s reasonable to talk about the correspondence between these two representations. You might even want to try to prove them isomorphic. But please don’t introduce trees as a special case of graphs.
NOTE: this text is a brief overview intended for instructors of a CS course that we’re developing; it is not technical. It tries to make the case that our early courses should steer students toward understanding problems in terms of pure functions. If you have suggestions or feedback, I’d love to hear them/it.
This section of the course introduces functions, a crucial topic in the field of computer science AND in the field of math.
Programmers and mathematicians sometimes think about the term “function” somewhat differently. Furthermore, some people who are familiar with both fields assign different meanings to the word “function” in the two fields.
The definition of a function in the mathematical domain is fairly well specified, though of course things get a little fuzzy around the edges. We’re going to define functions as the arrows in the category Set, more or less (if that’s not helpful, ignore it). That is, a function has a specified domain and a specified codomain, and it maps every element of the domain to a particular element in the codomain. There’s no requirement that it map every element of the domain to a different element of the codomain (one-to-one) OR that there be some element of the domain that maps to any chosen element of the codomain (onto). This (I claim) is the standard notion of “function” in math.[*]
Programmers also use and love functions. Nearly every programming language has a notion of functions. Of course, they’re sometimes called “procedures” or even “paragraphs” (I believe that’s COBOL. Yikes.). In programming, functions are often thought of as being elements of abstraction that are designed to allow repetition. And so they are. But it turns out that they also, in most modern programming languages, can be thought of as mathematical functions. Well, some of them can.
For many functions, this is totally obvious. If I consider the function from numbers to numbers that we might write in math class as f(x) = 14x + 2, then I can write that as a function in most programming languages. (If you disagree with me, hold that thought.)
But… things aren’t always so clear. What about a function that doesn’t return at all? What about a function that takes input, or produces output? What about a function that mutates an external variable, or reads a value from a mutable value? What about a function that signals an error? All of these present problems, some more substantial than others. None of these have a totally obvious mapping to mathematical functions.
There certainly are ways to fit these functions into mathematical models, but in general, the clearest lesson is that when there is a natural way to express a problem using functions that map directly to mathematical functions, we should. These are generally called “pure” or “purely functional” functions.
So, why should it matter whether our functions are pure? What benefits do we gain when we express functions in purely functional ways?
The clearest one is predictability, also known as debuggability and testability. When I write a pure function that maps the input “savage speeders” to 17, then I know that it will always map that string to 17; I don’t need to worry that it will work differently when the global foo counter is less than zero, or when it’s run in parallel, or on Wednesday, or when the value in memory location 0x3342a7 is less than the value in memory location 0x3342a8.
Put differently, pure functions allow me to reliably decompose problems into sub-pieces. When I’m debugging and testing, I don’t need to worry about setup and teardown to establish external conditions.
Another way to understand this is to dip into functions that use mutation. If we want to model these as mathematical functions, we need to understand that in addition to their stated inputs, they take additional hidden inputs. In the simplest case, this may be the value of a global counter. Things get much more complex when we allow mutation of data structures; now we need to worry about whether two values are the “same” value; that is, whether mutating one of them will change the other. Worse still, mutating certain values may affect the evaluation of other concurrent procedures.
For these reasons and others like them, pure functions are vastly easier to reason about, debug, and maintain. Over time, many of our programming domains and paradigms are migrating toward primarily-pure settings. Examples include the spread of the popular map-reduce frameworks, and the wild explosion of popularity in deep learning networks. In both cases, the purity spreads downward from a mathematical framework.
Note that it is not always the case that pure approaches are the most natural “first choice” for programmers, especially introductory programmers, for whom programs are often imagined as a “sequence of changes”; do this, then do this, then do this, then you’re done. In this model, the program is performing a series of mutations on a larger world. Helping introductory programmers move to a purer model is a challenge, but one with substantial payoff.
For this reason, this section focuses directly on pure functions, and invites students to conceive of programs using the models that they’ve been taught in elementary and secondary school, most particularly tables mapping inputs to outputs.
[*] The only reason I mention the category Set is to draw attention to the distinction between “codomain” and “range”; every function has a named codomain, regardless of whether its range covers it. For instance, the “times-two” function from Reals to Reals is a different function from the “times-two” function from integers to integers, and the “times-two” function from integers to reals is yet a third function.
I’m teaching a class to first-year college students. I just had a quick catch-up session with some of the students that had no prior programming experience, and one of them asked a fantastic question: “How do you know what library functions are available?”
In a classroom setting, teachers can work to prevent this kind of question by ensuring that students have seen all of the functions that they will need, or at least that they’ve seen enough library functions to complete the assignment.
But what about when they’re trying to be creative, and do something that might or might not be possible?
Let’s take a concrete example: a student in a music programming question wants to reverse a sound. How can this be done?
Reading Daniel Dennett’s “From Bacteria to Bach and Back” this morning, I came across an interesting section where he extends the notion of ontology—a “system of things that can be known”—to programs. Specifically, he writes about what kinds of things a GPS program might know about: latitudes, longitudes, etc.
I was struck by the connection to the “data definition” part of the design recipe. Specifically, would it help beginning programmers to think about “the kinds of data that their program ‘knows about’”? This personification of programs can be seen as anti-analytical, but it might help students a lot.
Perhaps I’ll try it out this fall and see how it goes.
Okay, it’s week four of data structures in Python. In the past few days, I’ve read a lot of terrible code. Here’s a beautiful, horrible, example:
1 2 3 4 5 6 7 8 910111213141516171819202122232425
# An IntList is one of# - None, or# - Pair(int, IntList)classPair:def__init__(self,first,rest):self.first=firstself.rest=rest# standard definitions of __eq__ and __repr__ ...# A Position is one of# - an int, representing a list index, or# - None# IntList int -> Position# find the position of the sought element in the list, return None if not found.defsearch(l,sought):ifl==None:returnNonerest_result=search(l.rest,sought)if(l.first==soughtorrest_result)!=None:ifl.first==sought:return0else:return1+rest_result
This code works correctly. It searches a list to find the position of a given element. Notice anything interesting about it?
Take a look at the parentheses in the if line. How do you feel about this code now?
(Spoilers after the jump. Figure out why it works before clicking, and how to avoid this problem.)
It’s much closer to ‘go’ time now with Python, and I must say, getting to know Python better is not making me like it better. I know it’s widely used, but it really has many nasty bits, especially when I look toward using it for teaching. Here’s my old list:
Testing framework involves hideous boilerplate.
Testing framework has standard problems with floating-point numbers.
Scoping was clearly designed by someone who’d never taken (or failed to pay attention in) a programming languages course.
The vile ‘return’ appears everywhere.
But wait, now I have many more, and I’m a bit more shouty:
Oh dear lord, I’m going to have to force my students to implement their own equality method in order to get test-case-intensional checking. Awful. Discovering this was the moment when I switched from actually writing Python to writing Racket code that generates Python. Bleah.
Python’s timing mechanism involves a hideously unhygienic “pass me a string representing a program” mechanism. Totally dreadful. Worse than C macros.
Finally, I just finished reading Guido Van Rossum’s piece on tail-calling, and I find his arguments not just unconvincing, not just wrong, but sort of deliberately insulting. His best point is his first: TRE (or TCO or just proper tail-calling) can reduce the utility of stack traces. However, the solution of translating this code to loops destroys the stack traces too! You can argue that you lose stack frames in those instances in which you make tail calls that are not representable as loops, and in that case I guess I’d point you to our work with continuation marks. His next point can be paraphrased as “If we give them nice things, they might come to depend on them.” Well, yes. His third point suggests to me that he’s tired of losing arguments with Scheme programmers. Fourth, and maybe this is the most persuasive, he points out that Python is a poorly designed language and that it’s not easy for a compiler to reliably determine whether a call is in tail position. Actually, it looks like he’s wrong even here; I read it more carefully, and he’s getting hung up on some extremely simple scoping issues. I’m really not impressed by GvR as a language designer.
Earlier this year, I was talking to Kurt Mammen, who’s teaching 357, and he mentioned that he’d surveyed his students to see how much time they were putting into the course. I think that’s an excellent idea, so I did it too.
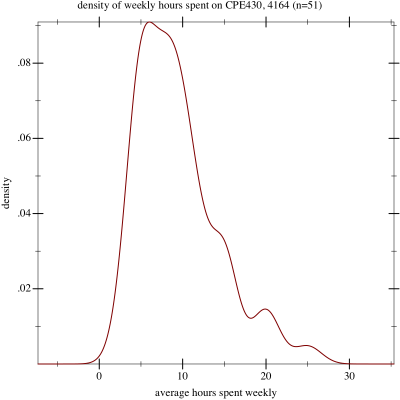
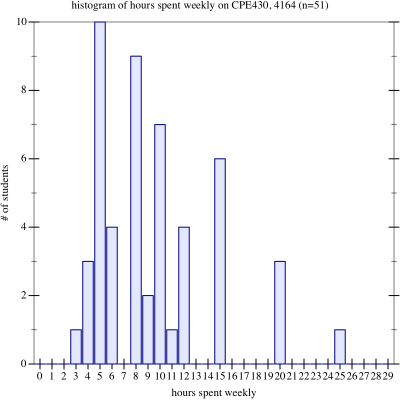
Specifically, I conducted a quick end-of-course survey in CPE 430, asking students to estimate the number of weekly hours they spent on the class, outside of lab and lecture.
Here are some pictures of the results. For students that specified a range, I simply took the mean of the endpoints of the range as their response.
Density of responses
Then, for those who will complain that a simple histogram is easier to read, a simple histogram of rounded-to-the-nearest-hour responses:
Histogram of responses
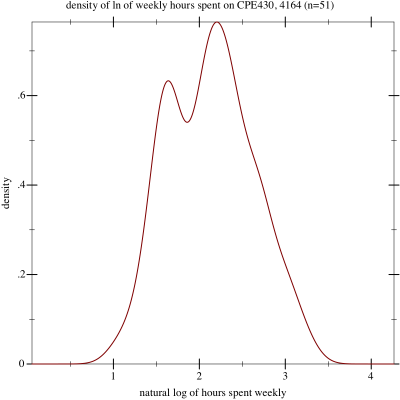
Finally, in an attempt to squish the results into something more accurately describable as a parameterizable normal curve, I plotted the density of the natural log of the responses. Here it is:
Density of logs of responses
Sure enough, it looks much more normal, with no fat tail to the right. This may just be data hacking, of course. For what it’s worth, the mean of this curve is 2.13, with a standard deviation of 0.49.
So here I am grading another exam. This exam question asks students to imagine what would happen to an interpreter if environments were treated like stores. Then, it asks them to construct a program that would illustrate the difference.
They fail, completely.
(Okay, not completely.)
By and large, it’s pretty easy to characterize the basic failing: these students are unwilling to break the rules.
One of my children is in third grade. As part of a “back-to-school” night this year, I sat in a very small chair while a teacher explained to me the “Math Practices” identified as part of the new Common Core standards for math teaching.
Perhaps the small chair simply made me more receptive, taking me back to third grade myself, but as she ran down the list, I found myself thinking: “gosh, these are exactly the same skills that I want to impart to beginning programmers!”
Make sense of problems and persevere in solving them.
Reason abstractly and quantitatively.
Construct viable arguments and critique the reasoning of others.
Model with Mathematics.
Use appropriate tools strategically.
Attend to precision.
Look for and make use of structure.
Look for and express regularity in repeated reasoning.
Holy Moley! Those are incredibly relevant in teaching programming. Furthermore, they sound like they were written by someone intimately familiar with the How To Design Programs or Bootstrap curricula. Indeed, in the remainder of my analysis, I’ll be referring specifically to the steps 1–4 of the design recipe proposed by HtDP (as, e.g., “step 2 of DR”).