Based on their full-page advertisements in various newspapers, Facebook is extremely upset about Apple’s upcoming move to make cross-app privacy the default. Their two main “hooks” are that it will hurt small businesses, and make the internet less “free”. I believe that neither of these is the case.
What is clear to me is that this move will hurt Facebook’s ability to collect piles of information about its users, and to leverage that to collect huge amounts of advertising money.
The Current Situation
Before I go on, a caveat here: while I’m a programmer and a researcher, I am not a security and privacy researcher, so you should check the things I’m telling you.
With that said, a brief summary of the current situation: Currently, Apple’s iOS includes a notion of an “IDFA”, an “identity for advertisers.” This IDFA can be seen by apps, and apps can send information about what a user is doing in this app back to its central servers. This information can then be connected to other information uploaded by other apps in order to build a detailed picture of you.
This allows Facebook and others to understand what you’re like, and how best to separate you from your money by presenting you with advertising that’s likely to convince you to buy things. It also allows Facebook to identify characteristics that will allow them to present content that you will be really really interested in.
Back in June 2020, at their developer’s conference, Apple announced a change to the way that IDFAs would work. Since this is a developer conference, they were addressing app developers, and telling them how they would use their new framework to observe a user’s IDFA:
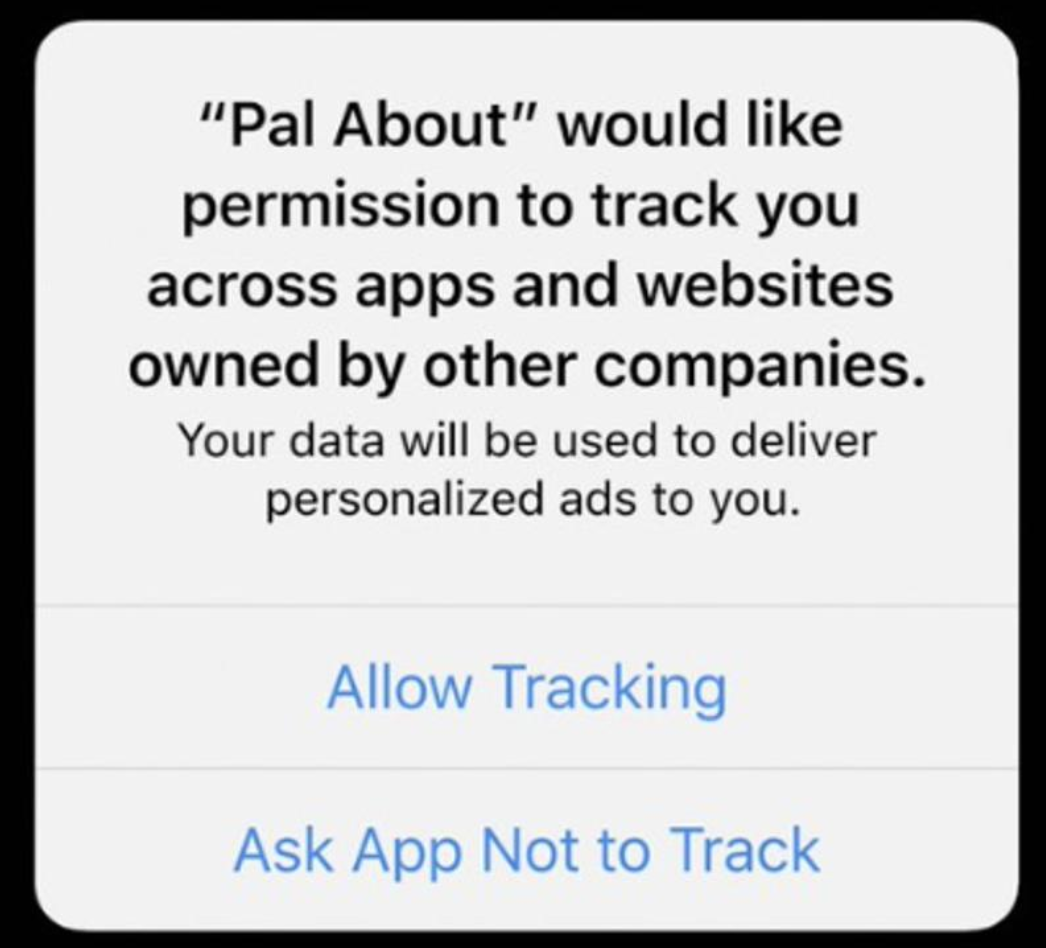
"To ask for permission to track a user, call the AppTrackingTransparency framework, which will result in a prompt that looks like this.
opt-in tracking dialog
This framework requires the NSUserTrackingUsageDescription key to be filled out in your Info.plist.
You should add a clear description of why you’re asking to track the user.
The IDFA is one of the identifiers that is controlled by the new tracking permission.
To request permission to track the user, call the AppTrackingTransparency framework. If users select “Ask App Not to Track,” the IDFA API will return all zeros."
So, which button would you click?
My guess is that relatively few people will click the “Allow Tracking” button.
This will mean that Facebook and other apps will not be able to observe your IDFA, and will not be able to use this extremely convenient way to gather and share information about you.
Small Businesses
What does this mean for small businesses?
Let me offer another caveat here, and tell you that I am not an expert on small businesses, their use of targeted advertising, and the effectiveness of their use of targeted advertising.
However, I’m going to observe that small businesses, by and large, are hurt by online advertising in general, and are unlikely to have the kinds of data science teams that are best positioned to sift through and profit from reams of consumer data.
Some (like Facebook?) might respond that their interfaces are designed to make high-quality data analytics available to even businesses that don’t have giant data science teams. I don’t think this argument holds much water, and I think that whenever Facebook provides better information on their users, companies with high data-science ability will be the ones best positioned to capitalize on it.
Facebook makes the specific claim that “Facebook data shows that the average small business owner stands to see a cut of over 60% in their sales for every dollar they spend.” This claim is (I claim) fairly preposterous; I’m guessing that they’re measuring the relative effectiveness of targeted and non-targeted advertising. What this ignores is the fact that people are still going to buy things, so that if targeted advertising goes away, more dollars will go toward non-targeted advertising.
Of course, they might be right, in the situation that the stuff that people are buying because of targeted advertising is worthless junk that they didn’t need. In that case, maybe targeted advertising is really important because it allows advertisers to sell us worthless junk. I’m not sure that’s a good argument for allowing targeted advertising.
The Free Internet
Next, Facebook makes the argument that this move is in opposition to the “free” internet. Specifically, they argue that “Many [sites] will have to start charging you subscription fees or adding more in-app purchases, making the internet much more expensive and reducing high-quality free content.”
This paragraph makes it clear that Facebook’s definition of “free” here is “free as in beer”, not “free as in speech”. That is, Apple’s change will not reduce the liberty of the internet. It will simply make it harder for sites to pay for their content-generation using targeted advertising.
Again, I think this argument doesn’t hold water, for the same reason given in the case of small businesses; unless the items being advertised are completely useless, shifting from targeted to untargeted advertising will simply level the advertising playing field, and make it harder for large companies to leverage their data science teams to separate you from your money.
However, a reduction in targeted advertising will make one huge difference; it will mean that small businesses will be more likely to work directly with the sites that their projected customers will use, rather than giving a huge slice of their money to middlemen like Facebook that mediate and control access to the targeted audiences. If I think that my customers read the Wall Street Journal, I will contact the Wall Street Journal and place an ad. This may sound like business as usual, but it’s absolutely terrifying to advertising middlemen whose current value is in holding all of the information about customers, and placing advertisements directly in the pages of those who are likely to click on them.
In Summary…
To summarize: tracking is still possible after this move; it’s just that users must opt into it, rather than having it on by default.
And here’s the thing. If you’re as terrified as this by the idea that users might have to explicitly consent to your practices… maybe you’re not actually the good guy.
Or, as That Mitchell and Webb Look put it: “Hans … are we the baddies?”
NOTE: this text is a brief overview intended for instructors of a CS course that we’re developing; it is not technical. It tries to make the case that our early courses should steer students toward understanding problems in terms of pure functions. If you have suggestions or feedback, I’d love to hear them/it.
This section of the course introduces functions, a crucial topic in the field of computer science AND in the field of math.
Programmers and mathematicians sometimes think about the term “function” somewhat differently. Furthermore, some people who are familiar with both fields assign different meanings to the word “function” in the two fields.
The definition of a function in the mathematical domain is fairly well specified, though of course things get a little fuzzy around the edges. We’re going to define functions as the arrows in the category Set, more or less (if that’s not helpful, ignore it). That is, a function has a specified domain and a specified codomain, and it maps every element of the domain to a particular element in the codomain. There’s no requirement that it map every element of the domain to a different element of the codomain (one-to-one) OR that there be some element of the domain that maps to any chosen element of the codomain (onto). This (I claim) is the standard notion of “function” in math.[*]
Programmers also use and love functions. Nearly every programming language has a notion of functions. Of course, they’re sometimes called “procedures” or even “paragraphs” (I believe that’s COBOL. Yikes.). In programming, functions are often thought of as being elements of abstraction that are designed to allow repetition. And so they are. But it turns out that they also, in most modern programming languages, can be thought of as mathematical functions. Well, some of them can.
For many functions, this is totally obvious. If I consider the function from numbers to numbers that we might write in math class as f(x) = 14x + 2, then I can write that as a function in most programming languages. (If you disagree with me, hold that thought.)
But… things aren’t always so clear. What about a function that doesn’t return at all? What about a function that takes input, or produces output? What about a function that mutates an external variable, or reads a value from a mutable value? What about a function that signals an error? All of these present problems, some more substantial than others. None of these have a totally obvious mapping to mathematical functions.
There certainly are ways to fit these functions into mathematical models, but in general, the clearest lesson is that when there is a natural way to express a problem using functions that map directly to mathematical functions, we should. These are generally called “pure” or “purely functional” functions.
So, why should it matter whether our functions are pure? What benefits do we gain when we express functions in purely functional ways?
The clearest one is predictability, also known as debuggability and testability. When I write a pure function that maps the input “savage speeders” to 17, then I know that it will always map that string to 17; I don’t need to worry that it will work differently when the global foo counter is less than zero, or when it’s run in parallel, or on Wednesday, or when the value in memory location 0x3342a7 is less than the value in memory location 0x3342a8.
Put differently, pure functions allow me to reliably decompose problems into sub-pieces. When I’m debugging and testing, I don’t need to worry about setup and teardown to establish external conditions.
Another way to understand this is to dip into functions that use mutation. If we want to model these as mathematical functions, we need to understand that in addition to their stated inputs, they take additional hidden inputs. In the simplest case, this may be the value of a global counter. Things get much more complex when we allow mutation of data structures; now we need to worry about whether two values are the “same” value; that is, whether mutating one of them will change the other. Worse still, mutating certain values may affect the evaluation of other concurrent procedures.
For these reasons and others like them, pure functions are vastly easier to reason about, debug, and maintain. Over time, many of our programming domains and paradigms are migrating toward primarily-pure settings. Examples include the spread of the popular map-reduce frameworks, and the wild explosion of popularity in deep learning networks. In both cases, the purity spreads downward from a mathematical framework.
Note that it is not always the case that pure approaches are the most natural “first choice” for programmers, especially introductory programmers, for whom programs are often imagined as a “sequence of changes”; do this, then do this, then do this, then you’re done. In this model, the program is performing a series of mutations on a larger world. Helping introductory programmers move to a purer model is a challenge, but one with substantial payoff.
For this reason, this section focuses directly on pure functions, and invites students to conceive of programs using the models that they’ve been taught in elementary and secondary school, most particularly tables mapping inputs to outputs.
[*] The only reason I mention the category Set is to draw attention to the distinction between “codomain” and “range”; every function has a named codomain, regardless of whether its range covers it. For instance, the “times-two” function from Reals to Reals is a different function from the “times-two” function from integers to integers, and the “times-two” function from integers to reals is yet a third function.
My name is John Clements. I’m a computer scientist and programmer, and quite frankly, it’s hard for me to remain civil in discussion of the Dickey amendment, one of the most pernicious pieces of legislative ledgermain it is my deep displeasure to be familiar with.
Since the Dickey amendment of 1996, the Centers for Disease Control—responsible for safeguarding the health of the American public—has been unable to perform research on the effects or causes of gun violence.
My government—the finest on earth—makes many decisions that I disagree with. Money is spent daily in ways that I am not in support of. However, when we institute a blanket ban on funding for research into particular topics, it sends a much stronger message; not only do we not want to spend money on this or that; we’re actually afraid to discover the truth. Senator Dickey himself—the author of the amendment—has since come out against the it1.
This tactic is one of a number of what I think of as “force multiplier” or “upstream” approaches to controlling society, and I think they’re all appalling. These tactics seek to change the rules of the game, to prevent our political system from working correctly. Gerrymandering is one such tactic. Allowing unlimited corporate donations—that is, the lack of campaign finance laws—are another. Rules such as this are similar; rather than trying to persuade the public that your point is correct, you simply prevent the truth from being discovered in the first place.
In my mind, this kind of ban seeks to prevent the free flow of information, tacks perilously close to freedom of the press, and can only come from a group that is frightened that the public might discover the truth.
On my way home from SIGCSE, I drew some more pictures.
This shows how each year of incoming students handles 357. Specifically, the x axis shows quarters since the students’ first one, and the y axis shows what fraction of the students have passed 357. Each line shows a different cohort.
Some of the lines are longer than others. This is because some cohorts that take a really long time to pass 357, and also because some cohorts haven’t yet had more than 6 or 9 or 12 quarters since entry.
There’s some sobering news here—since 2005, we’ve never managed to heave more than 75% of the students over the 357 bar.
However, looking more closely, we see that more recent cohorts—specifically, those since 2010 (a.k.a. “when we started 123”) look a lot better.
As part of our work on our recent SIGCSE paper (citation forthcoming), I took another look at our numbers of incoming students. The results surprised me. This table combines CSC, CPE, and SE students, and associates them with the quarter in which they first took a lower-level CS class.
The surprising thing about this—to me, anyway—is that our enrollments have actually been dropping over the past few years. I’m surprised.
Do we need to go through this again? Another entry on the list. Sarcasm aside, this gun really has no plausible purpose aside from killing people. Can we please have an assault weapons ban?
July 20, 2012 - Aurora, CO – 12 people dead - Smith & Wesson AR–151
December 14, 2012 - Sandy Hook elementary school, Newtown, CT – 20 people dead - Bushmaster AR–152
December 2, 2015 - San Bernardino, CA – 14 people dead - Smith & Wesson AR–153
June 12, 2016 - Orlando, FL – 49 people dead - Sig Sauer AR–154
October 2, 2017 - Las Vegas, NV – 57 people dead - “AR–15-style” assault rifle5
February 14, 2018 - Parkland, FL – 17 people dead - “AR–15 semi-automatic assault rifle”6